Huzaifa Arif
Ph.D. Candidate | Rensselaer Polytechnic Institute | Trustworthy AI Researcher

📧 arifh@rpi.edu | huzaifaarif20@gmail.com
📞 (518) 961-8482
I am a fifth-year Ph.D. candidate and researcher with multiple first-author publications in trustworthy AI. My work focuses on exposing and mitigating privacy and safety vulnerabilities in Large Language Models, demonstrated through research at IBM and LLNL.
I am open to collaboration.
Research Interests
My research spans several key areas in trustworthy AI:
- LLM Safety & Alignment: Parameter-efficient methods for steering large language models towards safe behavior
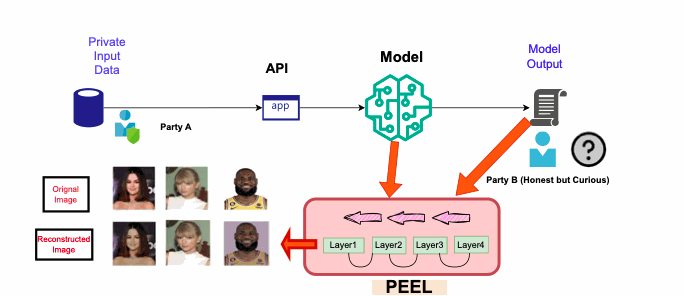
- Privacy in ML: Exposing and mitigating privacy vulnerabilities, including novel attacks like association leakage
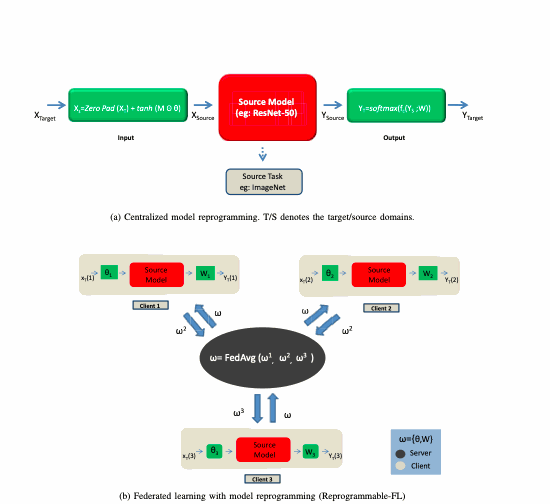
- Federated Learning: Improving utility-privacy tradeoffs through model reprogramming and differential privacy
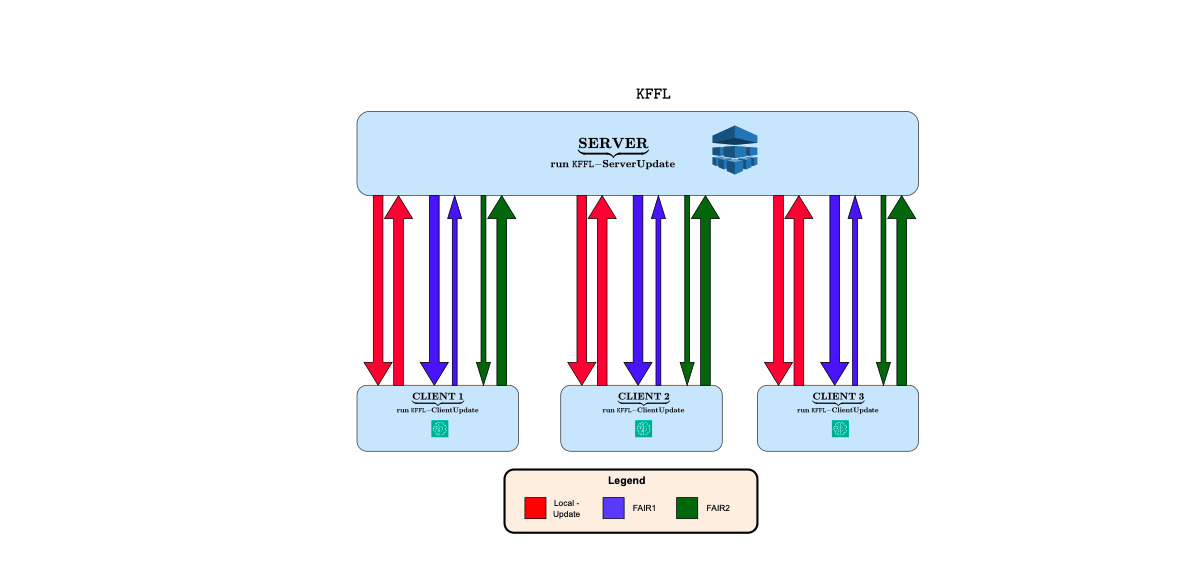
- Bias & Fairness: Developing algorithms for fair federated learning and mitigating demographic bias
news
| Dec 09, 2025 | 📈 Improved theoretical result of our previous work! “DS FedProxGrad: Asymptotic Stationarity Without Noise Floor” now on arXiv. Improved convergence analysis eliminating the noise floor dependence from my previous Group Fed Paper work! |
|---|---|
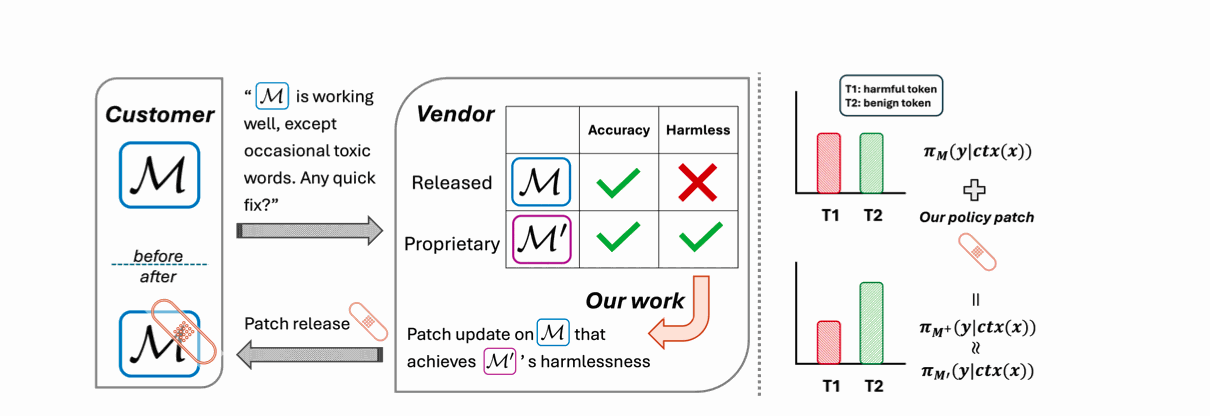
| Nov 11, 2025 | 🔬 New preprint released! “Patching LLM Like Software” work from IBM 2025 internship now available on arXiv. Lightweight safety improvements for large language models! |
| Sep 01, 2025 | 🏆 Awarded the Founders Award of Excellence (Top 1% Graduate Students at RPI) for excellence in academics and overall leadership. |
| Apr 15, 2025 | 🥈 2nd Place at the 3 Minute Thesis Competition for my thesis presentation. Listen to my pitch! |
| Apr 01, 2025 | 🎯 Successfully defended my PhD Candidacy Exam! |
| Dec 15, 2024 | 🏅 Awarded the Belsky Award for Computational Science and Engineering 2025 (Top 6 Graduate Students for Excellence in Research). Learn more |
| Dec 10, 2024 | 📄 Three papers accepted! Data leakage work from IBM internship accepted to SATML 2025, federated learning work to TMLR 2025, and weather prediction attacks from LLNL internship to AAAI 2025. |
| Oct 01, 2024 | 📚 Book chapter published! First author on “Utility Privacy Tradeoff” chapter in Federated Learning for Medical Imaging book. |
| Aug 01, 2024 | 📜 Patent published! “Reprogrammable FL” patent now publicly available (US20240256894A1). |
| Feb 01, 2023 | 🎉 IBM internship work published! “Reprogrammable-FL” research from IBM 2022 internship accepted to SATML 2023. Novel federated learning approach with model reprogramming techniques. |